PROOF
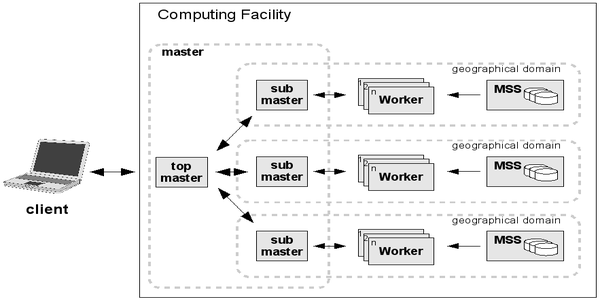
PROOF обеспечивает:
- Отсутствие (или очень малое количество) различий между сессией анализа, запущенной на локальном ROOT и отдаленной параллельной сессией PROOF. Типичный анализирующий скрипт должен работать одинаково.
- Отсутствие ограничений на число процессоров, которые могут использоваться параллельно.
- Адаптируемость сессии к изменениям в отдаленной окружающей среде (изменениям загрузки на узлах кластера, сетевым прерываниям, и т.д.).
В реализации PROOF подчиненные серверы - "workers" - являются активными компонентами, которые запрашивают главный сервер для получения новой работы всякий раз, когда они готовы ее проделать. Основная цель PROOF - минимизировать время выполнения общей задачи при наличии всех работающих workers, заканчивающих назначенную им задачу в одно и то же время. В этой схеме производительность параллельной обработки является функцией продолжительности выполнения каждого небольшого задания, "пакета"- объема работы, назначенного на worker, и пропускной способности сети. Основным параметром настройки является размер пакета. Если размер пакета слишком мал, то эффект от параллелизма будет снивелирован тратой времени на передачу служебных данных, вызванной перемещениями многих пакетов по сети между ведущим и ведомым серверами. Если размер пакета слишком велик, эффект разницы в производительности недостаточно выражен. Другим очень важным фактором является местоположение данных. В большинстве случаев необходимо обработать большое количество файлов данных, которые распределены по различным узлам кластера или отделены друг от друга географически. Для группировки этих файлов вместе используется цепочка, которая обеспечивает единый логический просмотр многих физических файлов.
Пакет представляет собой простую структуру данных из двух чисел: «начальное событие» и «количество событий». Размер пакета определяется динамически после работы workers в реальном времени. Главный сервер - "мастер" генерирует пакет при запросе ведомого сервера с учетом времени, потраченного на обработки предыдущего пакета и размера файлов в цепочке. Мастер сохраняет список всех сгенерированных пакетов на один из подчиненных серверов, поэтому в случае, если какой-либо "worker" "умирает" во время обработки, все его пакеты могут быть переработаны остальными "workers". В принципе пакет может быть столь же маленьким как основная единица обработки - событие.
Чтобы использовать PROOF, пользователь (клиент) должен начать сессию PROOF. Практически это означает создание объекта класса TProof или указателя на него.
Этот класс управляет Parallel ROOT Facility на кластере. Он запускает серверы workers, отслеживает их работу, статус и другие хпрактеристики, передает сообщения для всех workers, собирает результаты и т.д. Полное описание класса TProof можно посмотреть здесь. Мы рассмотрим только основные методы TProof.
Метод
запускает Proof сессию на определенном кластере. Первый параметр - URL, представляющий сетевой адрес master-узла кластера. Второй параметр - сonffile - это имя конфигурационного файла, описывающего удаленный PROOF-кластер (этот аргумент позволяет вам описывать различные конфигурации кластера). По умолчанию используется файл proof.conf. Третий параметр - confdir - это каталог, в котором находятся файл конфигурации и другие связанные с PROOF файлы (например, файлы motd и noproof).
Метод
выводит на экран итоговый статус сессии. По умолчанию он показывает информацию о клиенте и master, о версии ROOT, платформе, местоположении каталогов пользователей, число активных и неактивных workers, реальное время работы и время CPU и вводе/выводе, используемых в сессии, и т.д. и т.п.
Метод
позволяет выполнять команды ROOT на workers или на master. Например, PROOF диагностирует команды CINT, требующие файла ('.L', '.x' и '.X'), и удостоверяется, что обновленная версия файла существует на узлах. Файл загружается, только если это необходимо.
Метод
указывает PROOF, сколько вспомогательных узлов использовать параллельно.
При запуске макроса в первый раз можно заметить некоторое время ожидания из-за его распределения по workers. При запуске во второй раз и далее, если макрос не изменился, то он идет намного быстрее. По умолчанию команда выполняется только на workers, а не на master. Чтобы выполнить ее на master, можно сделать следующее:
Метод Process имеет несколько типов интерфейса:
Long64_t first = 0)
Обрабатывает набор данных, реализованный в ROOT специальныи классом TDSet, используя указанный файл селектора (.C) или объект TSelector.
Long64_t first = 0)
Обрабатывает набор данных (TFileCollection), используя указанный файл селектора (.C) или объект TSelector.
Общая (не основанная на заранее отобранных данных) обработка селектора: метод Process() указанного объекта селектора (.C) или TSelector вызывается «n» раз. Что же такое селектор?
Селектор
Чтобы быть в состоянии выполнить распараллеливание на уровня события, PROOF должен регулировать поток выполнения событий. Это требует, чтобы код был определен заранее, но при этом имел гибкую структуру. В ROOT это требование обеспечивается структурой Селектор, определенной абстрактным классом TSelector, который определяет три логических шага:
Begin - Начало, где задаются входные данные, параметры, файл для вывод; выполняется на клиенте и workers;
Process - Процесс, где делается фактическая работа; вызывается для каждого события, на workers. Именно эта часть может быть распараллелена;
Terminate - Финал, где обрабатывают результаты (фитируют, визуализируют...); вызывается клиентом и workers.
То есть схематично можно представить структуру Селектора следующим образом:
void Terminate() - обработка и вывод данных на клиенте, исполняется один раз на клиенте
Packetizer
Packetizer ответственен за балансировку нагрузки между workers. Он решает, где каждый кусок работы - пакет - должен быть обработан. Объект packetizer создается на master узле. Работа workers, а также скорость передачи различных файлов могут значительно мениться. Чтобы динамично уравновесить распределение работы, packetizer использует pull архитектуру: когда workers готовы к последующей обработке, они просят у packetizer следующий пакет.
Рассмотрим пример, в котором создается одномерная гистограмма и заполняется случайными числами, подчиняющимися распределению Гаусса. Сначала напишем скрипт для обычной сессии ROOT без использования PROOF.
#include "TH1F.h"
#include "TRandom.h"
#include "TCanvas.h"
void gauss(Int_t n=100000){
TH1F *fH1F = new TH1F("FirstH1F","First TH1F in PROOF",100,-10,10);
TRandom *fRandom=new TRandom3(0);
for(Int_t i=0;i<n;i++){
Double_t x=fRandom->Gaus(0.,1.);
fH1F->Fill(x);
}
TCanvas *c1=new TCanvas("c1","Proof ProofFirst canvas",200,10,400,400);
fH1F->Draw();
c1->Update();
}
Красным цветом в скрипте выделены определения гистограммы и генератора случайных чисел. Синим цветом - непосредственная работа скрипта - в данном случае генерация случайного числа и заполнение им гистограммы. Зеленым цветом выделен вывод данных - создание canvas и рисование на нем гистограммы.
Теперь для выполнения той же самой работы параллельно, с использованием PROOF, создадим класс ProofFirst, производный от абстрактного класса TSelector. Описание и методы методы класса TSelector можно посмотреть здесь. Заголовочный файл ProofFirst.h имеет вид:
#ifndef ProofFirst_h
#define ProofFirst_h
#include < TSelector.h >
#include "TH1F.h"
#include "TRandom.h"
#include "TCanvas.h"
class TH1F;
class TRandom;
class ProofFirst : public TSelector {
public :
TH1F *fH1F;
TRandom *fRandom;
ProofFirst();
virtual ~ProofFirst();
virtual Int_t Version() const { return 2; }
virtual void Begin(TTree *tree);
virtual void SlaveBegin(TTree *tree);
virtual Bool_t Process(Long64_t entry);
virtual void SetOption(const char *option) { fOption = option; }
virtual void SetObject(TObject *obj) { fObject = obj; }
virtual void SetInputList(TList *input) { fInput = input; }
virtual TList *GetOutputList() const { return fOutput; }
virtual void SlaveTerminate();
virtual void Terminate();
ClassDef(ProofFirst,2);
};
#endif
а файл реализации ProofFirst.C -
#include "ProofFirst.h"
#include "TH1F.h"
#include "TRandom3.h"
//_____________________________________________________________________________
ProofFirst::ProofFirst()
{
// Constructor
fH1F = 0;
fRandom = 0;
}
//_____________________________________________________________________________
ProofFirst::~ProofFirst()
{
// Destructor
if (fRandom) delete fRandom;
}
//_____________________________________________________________________________
void ProofFirst::Begin(TTree * /*tree*/)
{
}
//_____________________________________________________________________________
void ProofFirst::SlaveBegin(TTree * /*tree*/)
{
fH1F = new TH1F("FirstH1F", "First TH1F in PROOF", 100, -10., 10.);
fOutput->Add(fH1F);
fRandom = new TRandom3(0)0;
}
//_____________________________________________________________________________
Bool_t ProofFirst::Process(Long64_t)
{
if (fRandom && fH1F) {
Double_t x = fRandom->Gaus(0.,1.);
fH1F->Fill(x);
}
return kTRUE;
}
//_____________________________________________________________________________
void ProofFirst::SlaveTerminate()
{
}
//_____________________________________________________________________________
void ProofFirst::Terminate()
{
TCanvas *c1 = new TCanvas("c1", "Proof ProofFirst canvas",200,10,400,400);
fH1F = dynamic_cast(fOutput->FindObject("FirstH1F"));
if (fH1F) fH1F->Draw();
c1->Update();
}
Гистограмму и генератор случайных чисел объявляем как члены-данные класса ProofFirst (красный цвет). В конструкторе класса инициализируем значением 0 указатели гистограммы и генератора. В деструкторе уничтожаем генератор случайных чисел. Гистограмма принадлежит списку вывода, поэтому ее не уничтожаем. Метод SlaveBegin() создает экземпляры гистограммы и генератора случайных чисел (красный цвет). Основная работа выполняется методом Process(), в данном случее - это генерация случайного числа и заполнение им гистограммы (синий цвет). В заключение метод Terminate() показывает результат на терминале (зеленый цвет).
Теперь у нас все готово для обработки этот селектора. Поэтому запускаем PROOF
и вызываем метод
Вот что Вы должны увидеть на Ваших экранах:
По следующей ссылке можно найти более сложный пример: считывание дерева, вычисления, заполнение гистограмм, фитирование.